

Due to the rapid acceleration in new coronavirus literature, it becomes difficult for the medical research community to keep up. There is a growing urgency for innovative approaches, like recent advances in Natural Language Processing, to understand and analyze the abundance of medical/scientific articles.
Therefore, we composed a team of data scientists to start working on this challenge. In a first iteration we participated in the Kaggle COVID-19 Open Research Dataset Challenge. We contributed by building an interactive visualization to explore the hidden topics in the COVID-19 literature.
However, our ultimate goal is to help researchers to easily find articles in the existing literature that describe exactly those topics they are interested in. Therefore, we created a powerful Natural Language Processing tool in Dash (Python framework for building web applications).
Cookbook
Basically the “Covid-19 Literature Search Tool” has two main sections: a left panel for filtering and selecting articles and a right panel for browsing relevant content of the selected articles.
Click on the figure below and see for yourself how it works!
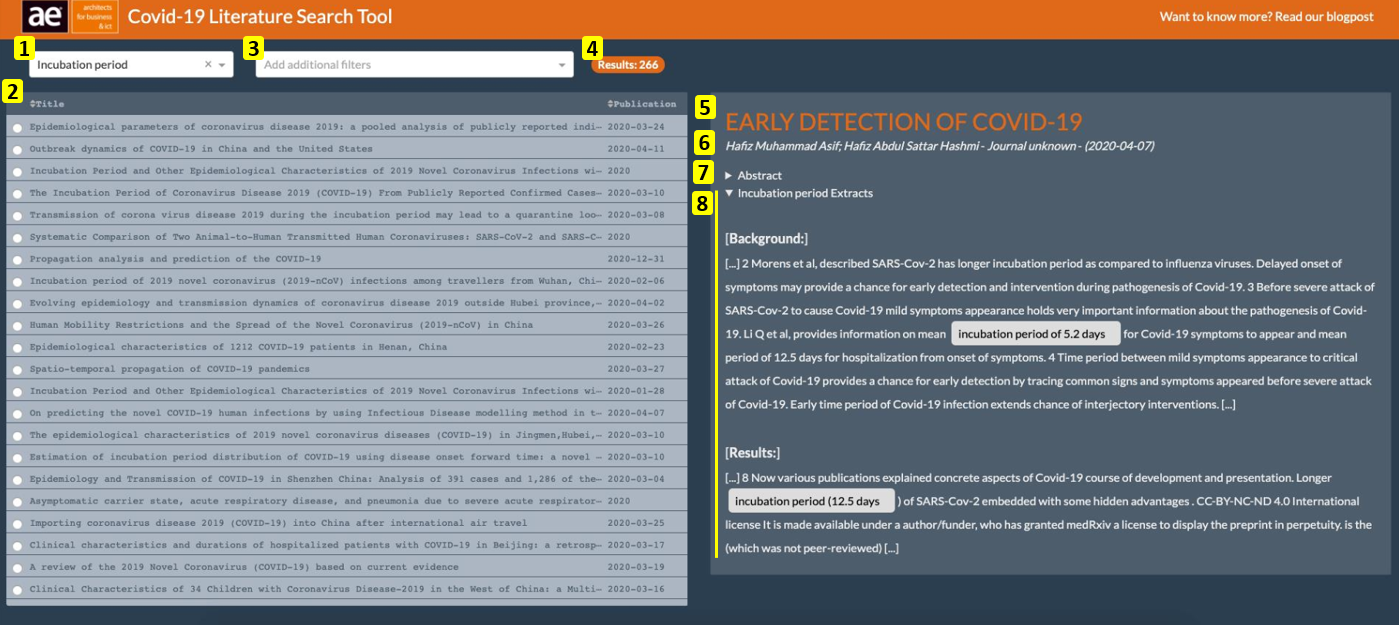
On the left panel the user can filter the existing articles on a wide range of relevant search queries by means of a dropdown (1). Examples of available search queries are:
- Incubation period
- Mortality rate
- Transmission rate
- Risk factors
- Diagnosis & treatment
- ...
The results of the selected search query are displayed in a table below (2). More precisely, whenever the body of the text of a certain paper deals with the selected search query, it will be added to the list. Note that the papers are listed according to how frequent a certain search term appears within the article.
Furthermore, it is also possible to refine your search results by adding one or more tags (3). These tags refer to search terms included in the title or abstract of a certain paper. It could for example be the case that a search query, like mortality rate, appears within the body of the text of a specific paper but is not mentioned within the abstract of that paper. This may indicate that the mortality rate of the virus is not the main subject of that paper.
In this way, the combination of both functionalities can help you to narrow down the list of obtained articles in a more intelligent way.
Note that also the total number of results is immediately displayed on top of the table (4).
On the right panel the selected paper is displayed. When clicking on the title (5), the user is navigated to a webpage where the full paper can be obtained. Together with the title, authors, journal (6) and abstract text of the paper (7), the reader will also be pinpointed to specific paragraphs of interest according to the selected search term (8). For every match found, the section title is displayed (in bold, between brackets) and also some context is given (= a few sentences before and after the found search term).
Note that due to poor quality of the input data, the section titles are not always properly displayed (see image below). For example, the section title may sometimes be empty or an incorrect title is given.

Behind the scenes
The COVID-19 Open Research Dataset (CORD-19) is a resource of over 52,000 scholarly articles, including over 41,000 with full text, about COVID-19, SARS-CoV-2, and related corona viruses. Since the corpus does not only consist of research papers specifically about COVID-19 we first needed to filter out those papers.
Therefore, we created a list of synonyms for SARS-CoV-2 (the virus itself) and COVID-19 (the disease caused by SARS-CoV-2). We checked if we could find one of the words (or word groups) from our list in the title or the abstract of a paper. When we could, we made the assumption that this paper was indeed about COVID-19. In this way, we reduced the set of relevant papers to 3130. Simple but effective.
Next, we needed a way to filter papers based on a list of predefined search patterns. On top, we wanted to be able to pinpoint readers directly to specific paragraphs of interest in a paper. We found that SpaCy's powerful Token Matcher functionality , could do the trick. It allows to match sequences of words (tokens), based on advanced pattern rules. You can, for instance, also take into account the part of speech category and the entity type of a word in your matching rule.
Let's take a look at an example. For the search query ‘mortality rate’ we defined a pattern that searches for sentences which include either the noun ‘mortality’ or ‘fatality’, followed by a number and the string ‘percent’ or the symbol ‘%’.
A Powerful Natural Language Engine
At AE, we created a powerful Natural Language Processing Engine that allows us to perform advanced and intelligent text processing tasks for a wide variety of use cases. In combination with Computer Vision techniques it becomes possible to automate even the most complex document handling tasks by transforming unstructured data from (scanned) documents into structured interpretable information and insights ready to be used in your processes. The techniques applied in our “Covid-19 Literature Search Tool” for example, can be used in any context where there is a need to make large bodies of text accessible and insightful.
Furthermore, the Natural Language Processing Engine also forms the foundation of our AI Powered Customer Care Agent, ADORE, a tool that identifies the issues from incoming mails and service requests to suggest the best possible solutions based on your historical data. This way,- ADORE takes a serious shortcut and drastically reduces repetitive work for customer service agents, even up to 80%. In addition we also applied our Natural Language Processing Engine in different data quality improvement and data enrichment tasks as well as automation of data entry processes.
Feel free to contact us if you want to know more or have any questions. In the meantime, stay safe, take care of yourself and each other!



